 YaoCheng8667 的个人博客
YaoCheng8667 的个人博客
记录精彩的程序人生
图模型训练论文笔记
1. Deep Graph Library: A Graph-Centric, Highly-Performant Package For Graph Neural Networks
【摘要】
提出了 DGL 的设计原则和具体实现,提取了 GNN 的模型计算范式,将其抽象成了通用的矩阵计算,目的是更好地实现并行化。优势是对比现有框架减少了内存占用同时提高了训练速度。
【Introduction】
总结了 GNN 的使用前景并提出需要一个 对研究人员而言灵活有理并且对实际应用而言高效能用的工具。
两个主要挑战:
- 现有的以张量为核心的深度学习框架与图之间存在语义鸿沟。
- 图的计算/存储的稀疏性和并行硬件,dense OP 之间存在性能差异。
主要贡献:
- 将 GNN 的计算步骤提取成一个用户可配置的消息传递模型。概括了前向和反向的稀疏矩阵运算用来进行硬件加速,同时探索了在此基础上的一些加速策略。
- 制定了以图为中心的编程抽象,主要表现在其代码库内将整个图的操作封装成了 DGLGraph 和 DGLHeteroGraph 类中,对外只暴露接口,底层可根据不同硬件进行不同的实现。
- 将 GNN 除模型以外的部分解耦,向下可以兼容 Tensorflow / pytorch, Mxnet 等多个框架。
【图神经网络和消息传递】
介绍了一下消息传递范式:将整个图的更新分为点上更新和边上更新两个步骤,对应消息函数,聚合函数,更新函数三个函数。
假设图可以表示成 \mathcal{G}(\mathcal{V}, \mathcal{E}), x_v \in R^{d_1} 表示节点 v 的特征,w_e \in R^{d_e} 表示边 (u, v, e) 的特征。
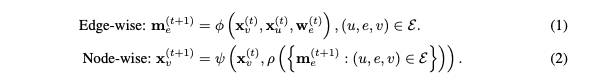
消息传递包含边上传递和节点传递两个阶段,边上传递的过程由消息函数 \phi 根据边和点的特征计算 message。每个节点有一个 mailbox 可以接收边传来的 message。之后聚合函数 \rho 聚合 message 并由更新函数 \psi 更新节点的特征。
GNN 中,通常 \phi 和 \psi 为神经网络,\rho 为 sum/mean/max(min)/LSTM 等 pooling 函数。
【通用的 SpMM 和 SDDMM】
消息传递和稀疏矩阵操作有很强的联系。本节总结了图模型计算中的两种矩阵运算的抽象,针对这两种不同的抽象可以进行硬件加速的优化以及接口的定义。
1. SPMM
指计算节点特征时稀疏矩阵和稠密矩阵相乘的操作(Sparse dense matrix multiply)。例如给定一个节点的特征矩阵 X \in R^{|v| \times d} 和图的邻接矩阵 A ,节点级的 GCN 可以表示成一个 sparse 矩阵和一个 dense 矩阵相乘Y=AX。
generalized SpMM 表示如下:
SpMM 由节点和边的特征输出节点的表示。
2. SDDMM
指计算边特征时的矩阵运算规则。例如很多 GNN 模型会计算边的权重。通常可以抽象为一个权重矩阵与邻接矩阵的点积,通常权重可由特征矩阵的点乘表示。
SDDMM 可以看成首先是两个 Dense 矩阵相乘,之后再与 Sparse 矩阵求点积。
generalized SDDMM 表示如下:
SpMM 由节点和边的特征输出节点的表示。
3. 与消息传递、并行的关系
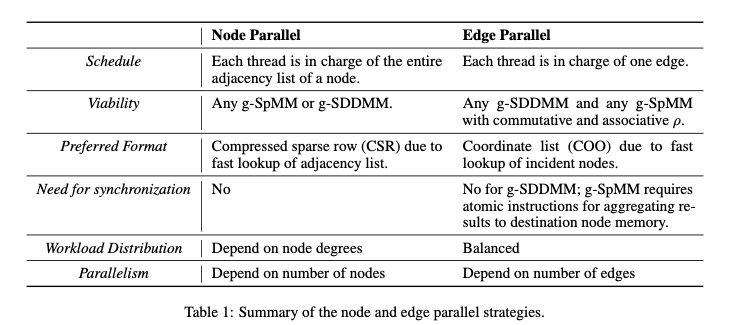
SPMM 对应节点级的更新,也就是聚合函数和更新函数。SDDMM 对应边上信息的更新,也就是 message 的计算。通俗的理解就是所有 GNN 的操作都可以抽象成矩阵之间的运算,按照输出数据的维度可以分为不同的两种抽象。做这两种抽象的原因是对于这两种计算选取的图的存储方式以及放到 GPU 上运行的方式可以不同,下表显示了这种不同。DGL 现在采用了一种启发式的策略去执行这两种并行,通常 g-SpMM 使用节点并行的方式,g-SDDMM 采用边并行的方式。
【DGL 系统设计】
1. Graph as a first-class citizen
- 以 Graph 为中心,使用 user-friendly 的抽象,允许底层深度优化。
- 框架中立性,通过接 Adapter 的方式可以实现无缝的应用迁移。
- 向下屏蔽了图存储的一些细节:CSR/CSC 分别用于前向和反向的 g-SpMM, COO 用于 g-SDDMM。
- 用户通过g.update\_all(\psi, \rho) 和 g.apply\_edges(\phi)去触发 g-SpMM 和 g-SDDMM 的 kernel,编译器会解析出给定的函数实现一个 fused_kernel。
- message reduce 阶段会按节点的 degree 分 bucket,每个 bucket 中的 msg 可以看成一个 dense tensor。
2. Framework-neutral design(框架中立性)
- 保留了对图模型计算中最关键的部分控制与实现,例如稀疏矩阵的管理与操作。
- 使用其他框架的 tensor 作为输入,并使用他们的 dense OP 及操作。DGL 定义了一些 shim(楔子)将其使用的 dense OP 映射到指定框架的实现,类似 ONNX。
【实验】
GPU 机器: 1 NVidia V100 GPU with 16GB GPU RAM and 8 VCPUs
CPU 机器: 64 VCPUs and 256GB RAM
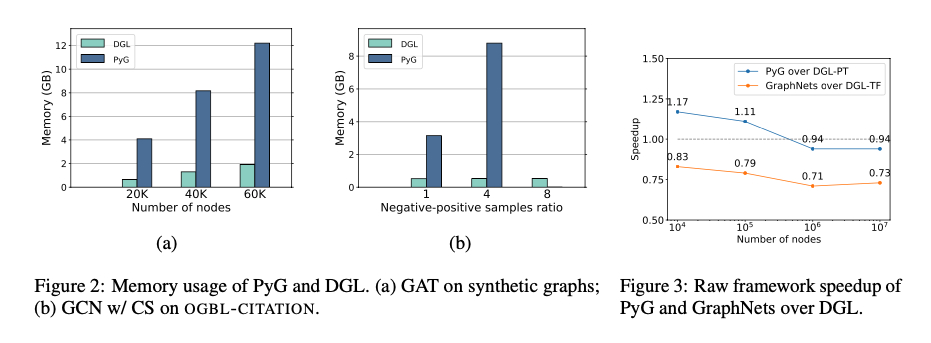
对比了不同数据集上 DGL 和 PyG、GraphNets 的性能差异,得到 DGL 在训练速度和内存消耗上都有较大优势。
2. Efficient Data Loader For Fast SAMPLING-BASED GNN Training On Large Graphs
【摘要】
提出了单机多卡上基于采样设计的 DataLoader,核心是利用可用的 GPU 资源做 Data 的 Cache,使用了一种轻量且有效的 Cache Policy。
提出了一种 GNN-computational-aware 的图 partition 算法,算法提高了 cache 的有效性,避免了 cross-partition 访问。
【问题描述】
通过实验的方式比较了 Neighbor-Sampling(每个节点取固定个数的邻居)和 Layer-wise Sapling(每一层 Layer 取固定数目的邻居)两种采样方式下训练数据加载时长占总时长的比例。
总结了现有 DGL 框架的几个问题:
- 数据加载时间占整个训练时间的绝大部分。
- 节点冗余访问问题。(存在一些热节点)。
- GPU 利用率不高(数据加载时间和训练时间不匹配导致的)。
- 数据加载和 GNN 的计算是线性的过程,没有流水线的操作。
【PA-GRAPH】
总体架构如下图所示:
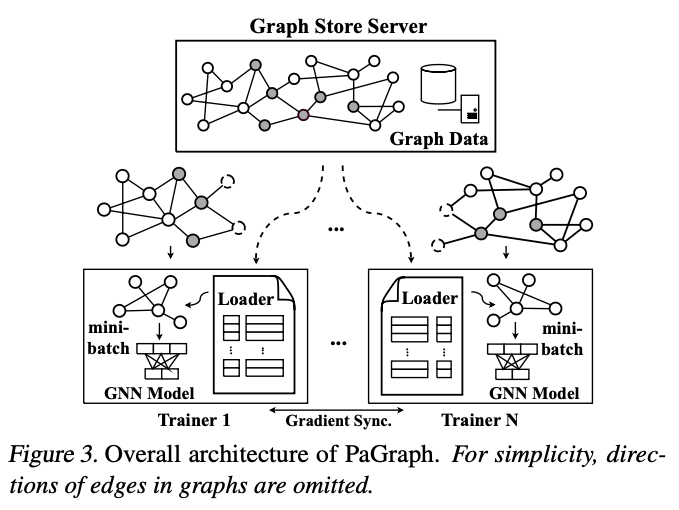
提出了 PA-Graph 框架及其 3 个核心技术:
- GNN 亲和的 Cache 机制,减少 CPU->GPU 的数据拷贝。
- 提出了一个 Cache 友好的数据并行训练方法。
- 数据加载和训练的 overlap。
1. GNN Computation-aware caching
(1) Cache policy
如果使用常规的对训练样本 random-shuffle 的方式,不能预测每个 mini-batch 中的节点,因为邻居是随机选择的,所以很难预测哪些节点会在下一个 mini-batch 被拿到。
所以提出了使用节点的 out-degree 作为节点被 select 可能性的标准,理由是一个节点的 out-degree 越大,该节点更有可能作为其他节点的 in-neighbor。文章同时认为动态 Cache 的方式不适合 GNN 的训练,因为 cache 数据是多个线程共享的,所以 PA-GRAPH 使用的 cache 策略非常简单,就是按照节点 out-degree 进行排序的静态 cache。
(2) Cache 大小
文中指出为了更好地利用宝贵的缓存,在不影响训练的前提下 Cache 的大小应该尽可能的大。所以在第一个 mini-batch 结束后可以得到可用的 Cache 大小。
2. 训练和 Partition 之间的数据并行。
文中指出 DGL 在多卡训练时采用的是模型并行的方式,也就是多个 GPU worker 拿到的是同一份图数据,这样做 cache 利用率很低,不能充分利用图访问的空间局部性,所以 PA-GRAPH 采用了数据并行的方法,每个卡负责自己的 partition,多个卡之间交换相互的梯度。以此为目标设计了一个图的 partition 算法。算法设计的目标主要考虑两方面(1)Trainer 之间负载均衡。(2)减少跨 partition 之间的重叠,在分 partition 的时候会同时存储边界节点的邻居,这些邻居节点不参与训练,目的是不去查全局的 store_server,如果这种重叠多了会造成存储浪费。
提出了一种贪心算法:总得 partition 数量固定的情况下,每个节点加入 partition 之前会计算一个 score,加入 score 最高的 partition 中。
TV_i表示 partition i 中当前训练节点的数目, IN(V_t) 表示该节点 n-hop 的邻居有几个在当前 partition 中,TV_{avg}表示每个 partition 应有节点数的期望值,|PV_i| 表示 partition i 中的总结点数,包括训练节点数和其 n-hop 内的邻居。
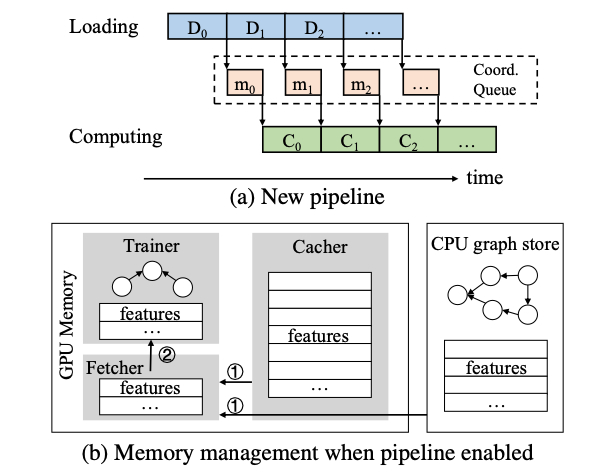
3. 数据加载和 GNN 训练的 pipeline
整个流分为 Loading 和 Computation,由 MsgQueue 进行交互和同步。
3. BGL:GPU-Efficient GNN Training by Optimization Graph Data I/O and Preprocessing
【摘要】
指出现有图模型训练系统不够高效的原因是为 GPU 准备数据态慢,该部分过程包括了子图的采样和特征提取。
提出了 BGL 框架,为了解决现有瓶颈,主要工作包括:
(1)设计了一个动态 Cache 引擎,减少特征检索的开销。
(2)改进了图的 partition 算法,减少了子图采样的跨 partition 之间的通信。
(3)通过资源隔离减少了数据预处理阶段的资源竞争。
【Introduction】
场景:图规模 20 亿节点,2 万亿边。按图采样每次取 mini batch 进行训练。每次迭代可以分为如下 3 个阶段:
(1)在分布式图存储服务器采样子图。
(2)子图的特征检索。
(3)GNN 的前向和反向计算。
指出了现有框架(DGL,PyG,Euler)存在的一些问题:
(1)取得训练样本需要大量数据传输。
(2)GPU 利用率不高,DGL,PyG 虽然采用了数据预取的方式,但在 large Graph 上只有 10% 左右的 GPU 利用率。
BGL 通过动态 cache 机制,图分隔算法改进和优化资源隔离的方式相较于 PaGraph, PyG, DGL 和 Euler 分别有 2.14x,3.02x,7.04x 和 20.68x 的加速比。在使用远程分布式存储的情况下依然可以使 V100 的 GPU 打满。
【设计】
Feature Cache Engine
1. Cache 算法
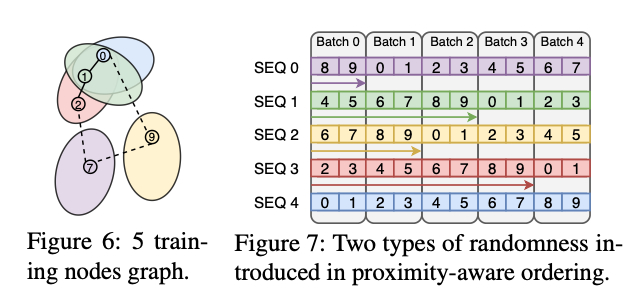
指出 PaGraph 中提出的静态 Cache 机制不适合大规模的图场景,所以 Cache 算法采用动态 Cache 的方式。首先调研了几种动态 Cache 的方式,FIFO 的性能 > LRU 或 LFU。提出采样顺序具有空间局部性,所以可以采用多源 BFS 的顺序进行采样。但该方法同样存在 trade-off,会造成模型收敛变慢。
所以在 bfs 的基础上加上了随机性的因素,使用多个 BFS 队列,随机选取若干个队列,并在采样过程中随机置换出其中一些队列。下图显示了这种双随机采样方式的流程,每个 batch 会从多个队列中取节点作为 training node,但对其中的负采样方法并未体积,估计是取与当前节点队列不同的节点作为负节点。
2. Cache 设计
Cache 设计采用 CacheMap+CacheBuffer 的方式(CPU+GPU 双级 Cache,均采取这种方式),其中 CacheMap 中存指针,CacheBuffer 中取具体的 BufferSlot,分布式存储采用分桶的方式,每个 GPU 中的 CacheMap 管理自己的 CacheBuffer,多卡之间的 CacheBuffer 通过 NvLink 连接。
3. Cache 的 workflow 和一致性保证
整个 Cache 的步骤如下
(1)将子图节点按 ID 进行分桶,将查询任务加入到一个 CacheQueryQueue(为了防止对 GPU 的访问出现线程竞争的现象,BGL 将这种访问都放到一个访问队列,有一个单独的线程专门负责,相较于使用锁减少了 8 倍的 overhead)。
(2)对 CacheQueryQueue 分配线程。
(3)通过 CacheMap 中查到指针进而访问 CacheBuffer。
(4)如果 GPU Cache Miss 会去查 CPU Cache,如果再 Miss 会去查 RemoteServer。
(5)如果查的是 RemoteServer,结果会立即送到 GPU,随后根据 Cache 替换规则更新 CacheBuffer 和 CacheMap。
Graph Partition
首先指出在大规模图训练场景下一个好的 Partition 算法应该具有如下特征:
(1)可以拓展到 10 亿节点的规模。
(2)一个节点多跳节点可以在一个或者很少量的请求中获得。
(3)各个 Partition 之间 training Node 应该负载均衡。
本文提出的 Partition 算法两大创新点:
(1)多级粗粒度的策略减少 partition 算法的复杂度,同时保持多跳之间的连接性。
(2)提出了一种启发式的新颖的节点分配方式,在保证连接性的同时保证训练节点的负载均衡。
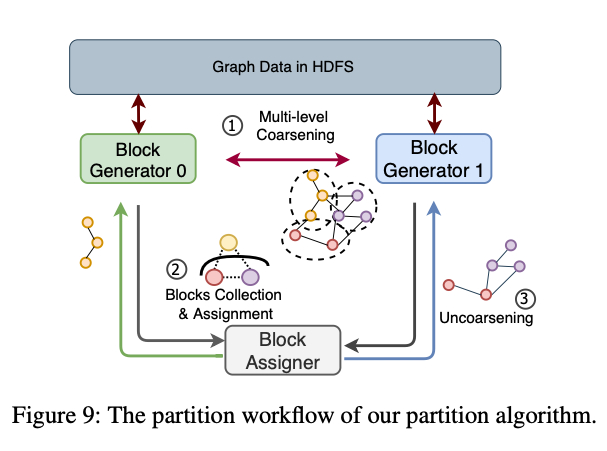
1. partition 模块 work-flow
整个 Partition 的 workflow 包含如下一些 Step:
- Step1:Coarsening
多源 BFS 将图切分成多很的 blocks,使用一种 random-partition 算法从 HDFS 加载数据。然后随机选一些源节点分配的 blockId,这些源节点可以通过 BFS 广播自己的 blockId。 - Step2: Assignment
利用下文提出的启发式 partition 算法将 blockId 分配到不同的 partition 上。 - Step3:Uncoarsening
利用 blockId -> PartitionId 的映射,将 block 映射到 nodes,然后将映射好的 nodes 送往 HDFS。
2. 启发式分配算法
采用一种贪心策略进行节点 partition 分配,综合考虑:
(1)加入 partition 的局部连接性。
(2)partition 内节点数目。
(3)跨 partition 交互的权重。
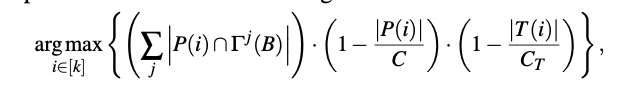
k 是 partition 号,P(i) 表示第 i 个 partition,\Gamma^j(B)表示该 block j hop 的所有邻居,T(i)表示第 i 个 partition 中训练节点的个数,C 和 C_T 均为惩罚系数。感觉跟 PaGraph 差不多。
Resource Isolation For Contending Stages
主要解决训练过程中对 CPU 的争用。将 GNN 训练过程分为了一个 8 级的异步流水线。
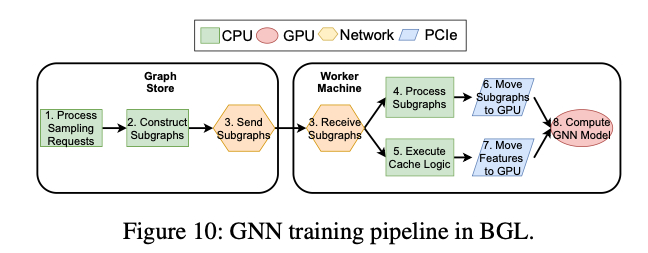
在流水线基础上考虑了(1)StoreServer 上处理采样请求和生成子图的 CPU 竞争。(2)子图处理和 Cache 机制对 WorkerServer 的 CPU 竞争。(3)子图和 Feature 向 GPU 拷贝对 PCIE 的竞争。
提出了一个最优化问题,解决之后可以算出 (1),(2) 中各自占用的 CPU 核心数和 (3) 中所占的 PCIE 带宽。
【实现】
重用了 DGL 的图存储模块,利用 GMiner 的图处理模块进行 Partition,和 DGL 团队合作进行上游开发。
FeatureCacheEngine
(1)使用一个单独的 CudaStream 去执行 Cache 逻辑。
(2)CPU 使用 OpenMP 加速 FIFO 的操作。
IPC
使用共享内存避免 IPC OverHead,Linux 端使用了 Linux SharedMem, Cuda 使用了 Cuda 的 IPC 库。
- 1. Deep Graph Library: A Graph-Centric, Highly-Performant Package For Graph Neural Networks
- 【摘要】
- 【Introduction】
- 两个主要挑战:
- 主要贡献:
- 【图神经网络和消息传递】
- 【通用的 SpMM 和 SDDMM】
- 1. SPMM
- 2. SDDMM
- 3. 与消息传递、并行的关系
- 【DGL 系统设计】
- 1. Graph as a first-class citizen
- 2. Framework-neutral design(框架中立性)
- 【实验】
- 2. Efficient Data Loader For Fast SAMPLING-BASED GNN Training On Large Graphs
- 【摘要】
- 【问题描述】
- 【PA-GRAPH】
- 1. GNN Computation-aware caching
- (1) Cache policy
- (2) Cache 大小
- 2. 训练和 Partition 之间的数据并行。
- 3. 数据加载和 GNN 训练的 pipeline
- 3. BGL:GPU-Efficient GNN Training by Optimization Graph Data I/O and Preprocessing
- 【摘要】
- 【Introduction】
- 【设计】
- Feature Cache Engine
- 1. Cache 算法
- 2. Cache 设计
- 3. Cache 的 workflow 和一致性保证
- Graph Partition
- 1. partition 模块 work-flow
- 2. 启发式分配算法
- Resource Isolation For Contending Stages
- 【实现】
- FeatureCacheEngine
- IPC